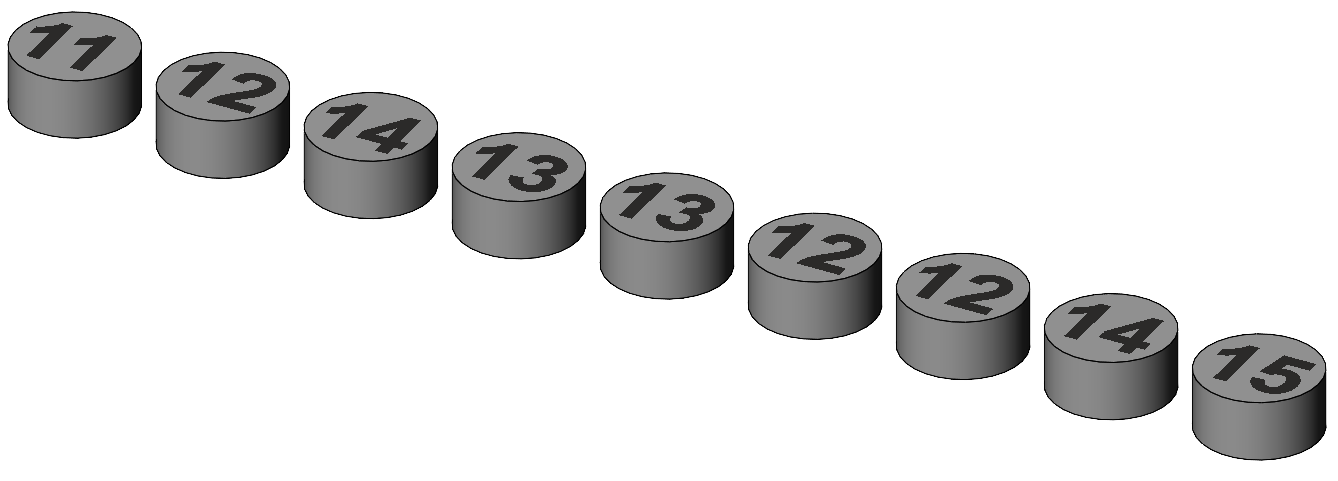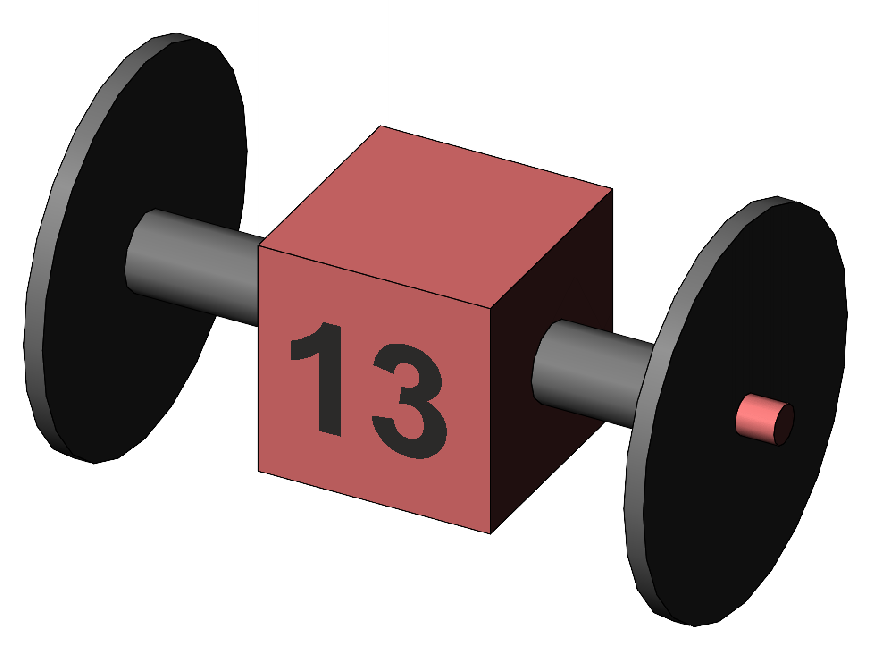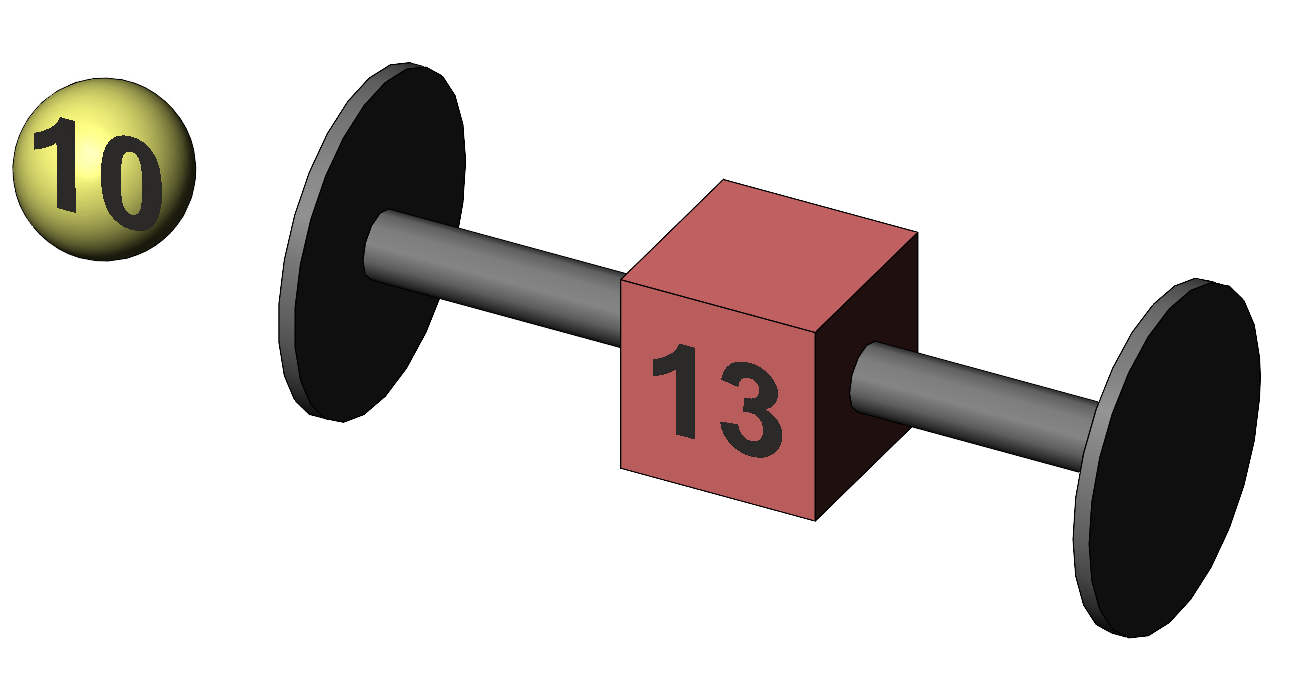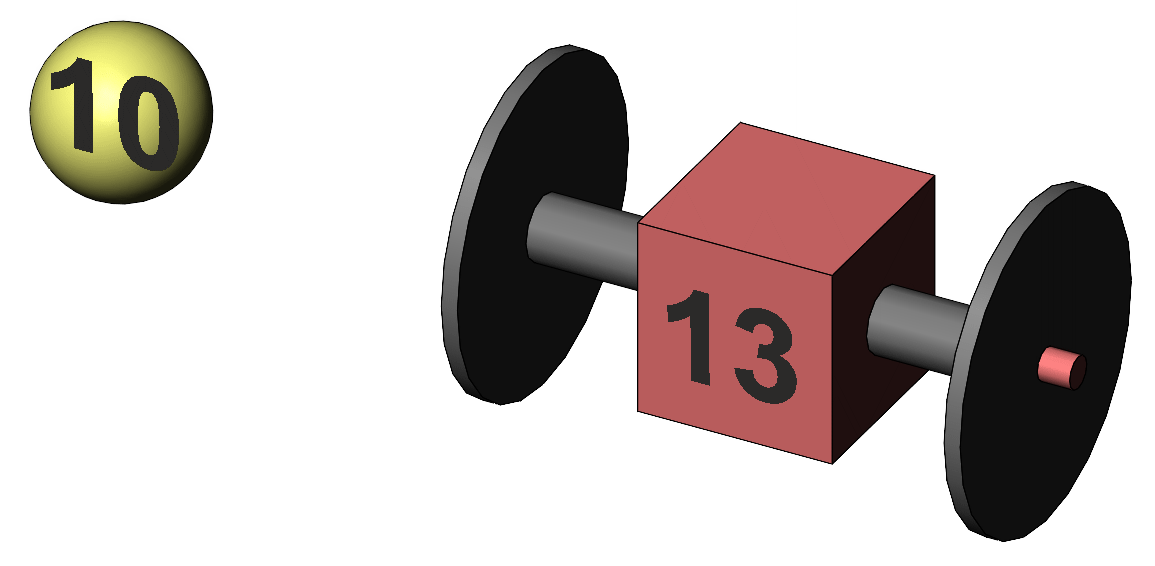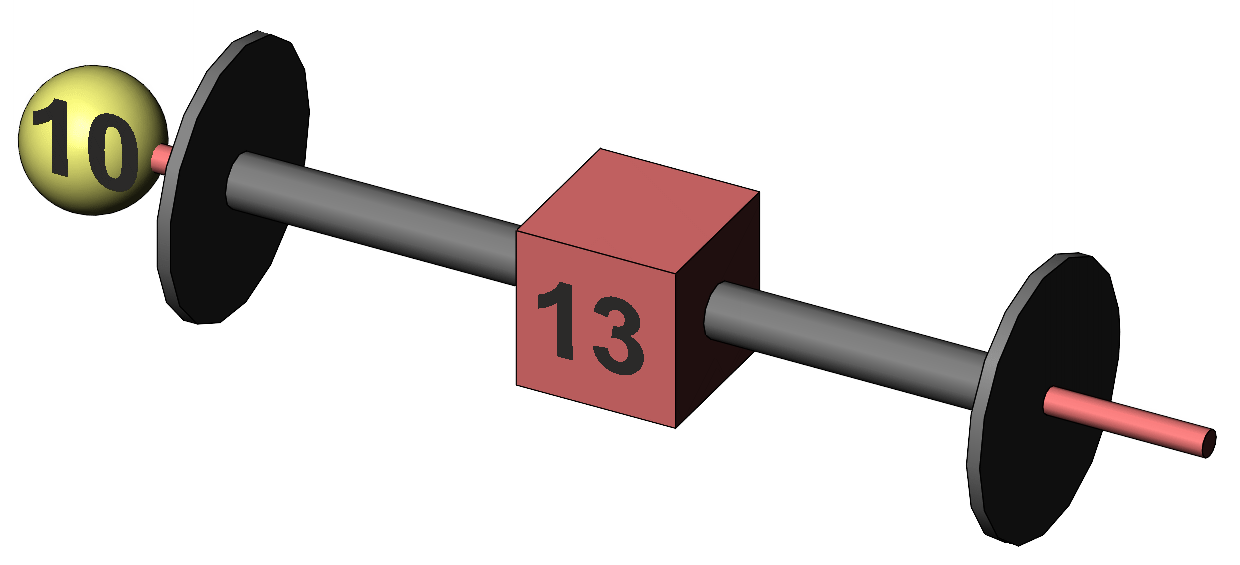![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
This page introduces the basic concepts of mean, variance, standard deviation, standard error, and significance, and in particular introduces the visual representations of these concepts that are used in subsequent pages. A group of 9 subjects undertake an experimental treatment and are then scored on a memory test. The data is shown in Table 1, where each subject is called a case. Table 1. Memory scores for experimental subjects.
The illustrations to come use a cylinder, disc, or tube to represent a data item or subject score. The data of Table 1 are illustrated as a line of discs in Figure 1.
Figure 1. Depiction of the subject scores of Table 1. We've done this experiment in order to see if the treatment improved the memory of our subjects. Assume that our memory test has been standardised on a large group of people and that the average memory score of the general population is 10. An answer to our implied question is given by comparing the average score on the memory test with the population average score of 10. Table 2 shows the mean score of our sample. We'll call it a mean rather than an average to be more technically appropriate. Table 2. Mean memory score for experimental subjects.
The mean of a set of data is represented by a cube, as in Figure 2.
Figure 2. Representation of the mean of a set of data.
The cube represents the value "13.0". Figure 3 imagines the subject individual data discs inside the cube. Usually, the cube hides the details of the data because we are usually interested in the mean as the relevant summary of that data.
Figure 3. Depiction of the individual data discs inside the cube representing its mean. It looks like there has been an improvement in mean memory score of 3. The illustration of the data relevant to our investigation is shown as Figure 4. We have the cube representing the sample mean, and a yellow ball representing a fixed value such as the population mean.
Figure 4. Representation of the comparison of a single sample mean to a fixed value of interest. Is this difference between the sample mean and the general population mean "real" or could it be a chance improvement? The probability of observing our difference of 3 by chance depends on two matters. One is the variability in our data; and the other is the size of our sample. But first we'll review the logic behind our analysis.
Logic of statistical inferenceThe conventional logic of statistical inference asks for the probability of observing an outcome by chance, if in fact the treatment has no effect. Again by convention, we will declare the difference to be significant (statistically speaking) if its probability of occurrence by chance is 5% or less. This value of 5%, or 0.05, is the level of significance and has the symbol "α". Of course, we could be wrong; the difference could indeed have occurred by chance and in this case we have committed a Type I error, labelling the difference "significant" when it was not. There are some key points about this logic. One is that deciding on the probability of some occurrence involves making some assumptions about our data and about what we mean by "chance", so we'll provide some discussion along the way which makes explicit what is being assumed. Whether our assumptions are acceptable is determined by the context; there is no right or wrong use of a statistic or statistical test, only a judgement about its utility and its appropriate interpretation in a given situation. Two is that the decision of what constitutes significance is quite arbitrary, and using α = .05 is entirely by convention. Some contexts may suggest a more stringent level such as .01, and other contexts may find value in labelling a result with p = .1 as "suggestive", depending upon their tolerance of a Type I error (declaring a result "real" when in fact it is due to chance). The other side of the coin is declaring a result as due to chance when in fact it is "real". This is a Type II error, β, and it is inversely related to α, smaller for large α and larger for small α. We may remember the concept of the power of a statistical test as its ability to correctly declare a result "real" when in fact it is real, given as 1 − β . What is important is to know that the power of a test depends upon the sample size, larger N giving more power. There are apps which calculate exactly how much power a particular sample size is likely to give. I have found G*Power 3.1(§1) to be particularly useful. Three is to keep in mind the distinction between "statistically significant" and "practically significant". There are many outcomes which are statistically significant but which have no practical value. Feynman's observation (§2) on seeing a car number-plate "ARW357" on the way to the lecture usefully reminds us that the exceptionally high statistical significance of this outcome, p<.000001, is matched only by its completely negligible practical value. Inferential statistics is often called the search for a signal amongst noise, and the choice of a value for α represents a trade-off of relative risk, which is a trade-off between an erroneous detection of a signal versus a failure to detect the signal. These risks have different costs depending upon their context. In some medical contexts, incorrectly declaring a treatment effective may be very costly, while in some research contexts it may be that failing to detect an effect is very costly. And the cost of deploying increased resources in order to increase N, hence to increase test power, is again dependent upon context and would usefully be informed by a cost-benefit analysis. §1 Faul, F., Erdfelder, E., Buchner, A., & Lang, A.-G. (2009). Statistical power analyzes using G*Power 3.1: Tests for correlation and regression analyses. Behavior Research Methods, 41, 1149-1160. Search for G*Power to download their PDF user guide. §2 In Goodstein, D.L. (1989). Richard P. Feynman, Teacher. Physics Today, 42(2), p. 73. Feynman was illustrating the need to specify a useful prediction ahead of time before testing for its occurrence. Some sort of pattern can always be found in data.
VariabilityAs a thought experiment we'll imagine the variability in our data was different. One situation is shown in Table 3 where one set of scores show lower variability, and another set where the scores show higher variability. The means are unchanged. Table 3. Lower and higher variability of scores.
The low variability set of scores range between 12 and 14 with most at 13. It certainly seems that these scores are all higher than 10, the average memory score of the general population, and the difference seems clear-cut. On the other hand, the high variability set of scores range between 7 and 19. It is not at all clear that they are, on average, higher than 10. Variability in a sample of data items is the degree to which the data items vary around or deviate from their mean. As a measure of variability we can calculate the variance. Here, the difference or deviation between a data item and the mean is squared, and the squared values are added together and averaged. The sum of the squared deviations is called sums of squares or SS, and their average is called the mean sum of squares or MS, and this is the variance. Not quite an average, however; instead of calculating the average using N, the number of items, we divide by the degrees of freedom of the items, N − 1. Variability is also conveniently measured by the standard deviation, which is the square root of the variance, and usually symbolised by "s". Convenient, because the units of s are the units of the data items, giving a linear measure. This allows us to discuss, for example, which data items are more than one standard deviation above the mean, or the value of a possible data item that is two standard deviations below the mean. Variance is in squared units and thus is a kind of measure of area (§3). Table 4 shows the variance of the sample data we've been looking at, along with their standard deviation, degrees of freedom, and sums of squares. Table 4. Variability measures for sample data.
§3 It would be an unusual discussion which asked about the "area" shown by the sample data, but it has value when considering the area of overlap between data. For example, it might be interesting to calculate the overlap or shared area of the memory test score and the age of the subject for our data. The correlation coefficient is the usual measure of the association between two variables such as memory score and age, but when squared it represents a shared overlap or area, being the amount of variance shared between the two variables. Sometimes it is important for an illustration to show us the connection of subject data with the date of the same subjects in another sample. Do do that, we show the subject data cylinders or tubes protruding out of the cube depicting the mean, as in Figure 5.
Figure 5. The representation of subject scores that are (or will be) connected with other scores of the same subjects in another cube (not shown here).
Sample sizeIn a second thought experiment, we'll consider smaller or larger samples, while keeping the same means and variances. Table 5 shows the summary statistics of three different sized imaginary samples. Table 5. Summary statistics for variously sized imaginary samples.
Other things being equal, we would be very confident in a mean of 13 if it was shown by a sample of N = 100 subjects, unsure for N = 9 subjects, and entirely unconvinced if shown by N = 2 subjects. We expect the mean of a sample to be more stable the larger the sample.
Standard errorThe expected stability, or conversely, the expected variability of a sample mean is measured by its standard error, often symbolised "SE", given by the sample s divided by the square root of the sample size, N. That is, the expected standard deviation of a value when that value is a mean of n data items is its standard error. The standard error integrates the variability in our data with the size of our sample to provide the measure we will need to decide on the probability of an improved memory score in our subjects. SE = s /√N This may well be the only equation you really need to remember in all of statistics. This relationship between sample variability and sample size is implied by the law of large numbers, and we can appreciate it intuitively. The law simply says that more data items are guaranteed to give more accurate results. The best estimate of the value of some variable of interest, such as the memory score of a population of people, is given by the average — that is, the total of the scores divided by N, the number of people whose score you have measured. It turns out the accuracy of this average is given by the "average" of the variance of the scores — that is, the variance divided by N, Var / N, or equivalently s /√N (§4). We can add the value of SE to our table, as in Table 6. Note that in these and other calculations on this page there may be rounding errors; the values reported here have been rounded to 2 decimal places, and calculations made with the rounded values may show minor disagreement in the second decimal place. Table 6. Standard error of the mean for variously sized samples.
Figure 6 illustrates a mean with different standard errors. The thinner red cylinder protruding from the mean cube represents the variability within the data set, s = 1.22. Because each sample s is the same, the thinner red cylinder length for each sample is the same. The thicker grey cylinder protruding from the mean cube with a terminating grey disc represents the variability of the mean, being its standard error of 0.87, 0.41, and 0.12 respectively. The length of the grey cylinder is plus and minus 1 SE on either side of the mean cube. The lengths of the grey and red cylinders are in proportion to the s and SE of their samples. Note how the terminating discs are further away from the cube representing the mean for a smaller sample size, and are closer to the mean for a larger N. Visually and conceptually, the discs are showing the degree to which the mean varies; the discs for smaller N are spread further apart than the discs for larger N.
Figure 6.
Representations of ±1 SE of the mean by thicker
grey cylinder and terminating grey disc.
§4 It may seem a little strange to call "Var / N" the "average" variance. Well, yes, that's why there are quotes around "average". If your statistical intuition is not yet very strong, we can provide a better conceptual account as follows. We imagine that we draw a large number of samples from a population, and for each sample we calculate its mean and variance. We treat each sample mean as a data item, and calculate the mean of this sample of sample means. Similarly, we calculate the variance of this sample of sample means which is the measure we are seeking, being the variability of the sample mean. Consider a sample of N data items X with mean M. A theorem in statistics tells us that the variance of a set of data items, where every data item is divided by a constant factor P, is equal to 1/P of the variance of the original data items, that is, Var [X/P] = [Var X]/P. The data items in our sample of sample means, M, are each the result of a division by N, that is M = X/N. Their variance is Var [M] = Var [X/N] and hence Var [M] = [Var X]/N.
Probability of the differenceWe have seen that the probability of observing our difference of 3 between the sample mean of 13 and the general population mean of 10 depends on the variability of our data and the sample size — specifically, upon the SE. The normal curve or Gaussian distribution is the appropriate model for the variability of a sample mean as given by the Central Limit theorem, and is considered applicable when the sample size, N, is larger than 30. Under the normal curve, we know that approximately 95% of the data is found between plus and minus two standard deviations (more exactly, z = 1.96). If we have a large sample (N > 30) we may expect a sample mean to only be smaller than its population mean by −2 SE or larger by +2 SE 5% of the time. Using our larger sample (N =100), the number of standard errors between our sample mean of 13 and the population mean of 10 is 3 / 0.12 = approximately 24.5. This is significantly larger than 2 (more exactly, 1.96) SE which is our critical value at α = 0.05. Using the same approach to calculate the significance of the difference for our original sample of N = 9, we find the number of standard errors is 3 / 0.41 = approximately 7.35, and when N = 2, it is 3 / 0.87 = approximately 3.46. We know, however, that the normal distribution is not an appropriate model for the probability of a certain number of standard errors when N < 30. Instead we should use the t distribution which requires us to specify the degrees of freedom (N − 1) when determining the appropriate number of standard errors — the critical value — which have a probability of 5% or less. Table 7 adds the critical values of t for our three sample sizes. Table 7. Critical values for variously sized samples.
The difference of 3 between the sample mean of 13 and the general population mean of 10 is 3.46 standard errors for the small N = 2 sample, and we see that it is not significant; the difference needs to be 12.71 or more standard errors, that is, a difference of 11 or more, in order to reach statistical significance. On the other hand, the difference of 3 is 24.5 standard errors for the larger N = 100 sample, and is highly significant. For such a sample, the difference only needed to be approximately 0.24 to reach statistical significance. This approach to establishing the significance of the difference between a sample mean and some interesting value uses a confidence interval. We construct a 95% confidence interval for the mean, and see whether the interesting value falls inside (not significant) or outside (significant) the interval. For a large sample, the 95% confidence interval around the mean is ±1.96 SE, approximately ±2 SE, and that is a very convenient round number to remember. For a smaller sample, the confidence interval is higher. When N = 9, it is ±2.31 SE, and for N = 2 it is a high ±12.71 SE (§5). Figure 7 illustrates the ±2 SE confidence interval around each mean in relation to the yellow ball value of interest. The intervals do not show the significance or otherwise of the difference, because the necessary critical value is not illustrated. The visual lack of overlap with the yellow ball seems encouraging and suggestive of a difference but is not conclusive.
Figure 7. Representations of a ±2 SE confidence interval around a sample mean in relation to a value of interest for samples of N = 2, N = 9, and N = 100 respectively. Instead, to use a confidence interval to correctly decide whether the value of interest lies inside or outside, the interval must be constructed using the critical value of t for the df involved. Figure 8 shows the outcome with the interval ±12.71 SE, where SE = 0.87 for sample N = 2. The outcomes for N = 9 and N = 100 are very similar to Figure 7 and are not shown.
Figure 8. Representation of a ±1 Crit.t·SE confidence interval around a sample mean in relation to a value of interest for sample N = 2. Out of interest, we can compare the outcomes for data which shows lower or higher variability, as per Table 8. Table 8. Outcomes for samples with lower or
higher variability.
Illustrations of these outcomes for a sample N = 9 with lower and higher variability are shown in Figure 9.
Figure 9. Representations of three tests of the difference between a sample mean and a value of interest using 2 SE with N = 9 when samples have lower or higher variability. §5 A sample size of N = 7 or larger is needed before the confidence interval ±Crit t · SE is smaller than the simple confidence interval ±2 s. The implication is that N = 7 is the minimum sample size when the balance between the small sample variability of the sample mean and of the sample standard deviation tips in favour of the mean. The further implication is that the relatively improved stability of the sample standard deviation with N >= 7 improves the credibility of the data if it is to be published. It may be useful to note that the general rule of thumb that a difference larger than approximately 2 SE is interesting becomes a rule of thumb of approximately 2.5 SE or less when N >=7. Another nice round number to remember for almost universal application.
SummaryConsider a sample of N data items with mean M and variance Var. The variability of M is given by Var / N, and expressed as a standard error, SE, given by s / √N. The question of whether the difference D between M and some fixed value is "significant" or "not significant" is examined by calculating the number of standard errors that the difference represents. This number of standard errors is usually called "t": t = D / SE. The probability of observing a given value of t is given by the t distribution for smaller N and the Gaussian for larger N, where the test statistic t = D / SE is referred to the t distribution with df = N−1 or the test statistic z = D / SE is referred to the normal distribution when N > 30. The difference is called significant by convention if the probability p of t or z is less than α. By definition, exactly α tests of significance will result in Type I errors. Next: Two independent samples and two dependent samples, testing the difference between two sample means and its connection with correlation and regression.
Using ExcelThe mean of a set of data is calculated by using the AVERAGE(range) function and the standard deviation by using STDEV.S(range). Although available, there is no reason to use STDEV.P. For large data sets, it may be convenient to determine N using COUNT(range). Degrees of freedom are calculated as N–1. The standard error SE may be calculated as STDEV.S(range)/SQRT(N) or SQRT(VAR.S(range)/N). The sums of squares are obtained from the variance multiplied by the degrees of freedom, SS = VAR.S(range)*(N-1). Excel does not provide a specific function to calculate a one sample t-test. To do this, the workflow is (1) calculate the difference between the sample mean and the value of interest; (2) calculate the sample standard deviation; (3) divide the standard deviation by SQRT(N) to give SE; (4) calculate the value of t = difference divided by SE; (5) calculate the probability of the t value using the function T.DIST.2T(t value,N–1). It may be useful to know the critical t for a given df and α. Calculate this using T.INV.2T(α,df). Excel provides a Z.TEST() function to refer a z statistic to the normal distribution. Use Excel "Help" and read its description very carefully — for example, "when sigma is omitted, Z.TEST(array,x) = 1- Norm.S.Dist((Average(array)- x) / (STDEV(array)/√n),TRUE)".
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
©2025 Lester Gilbert |