![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
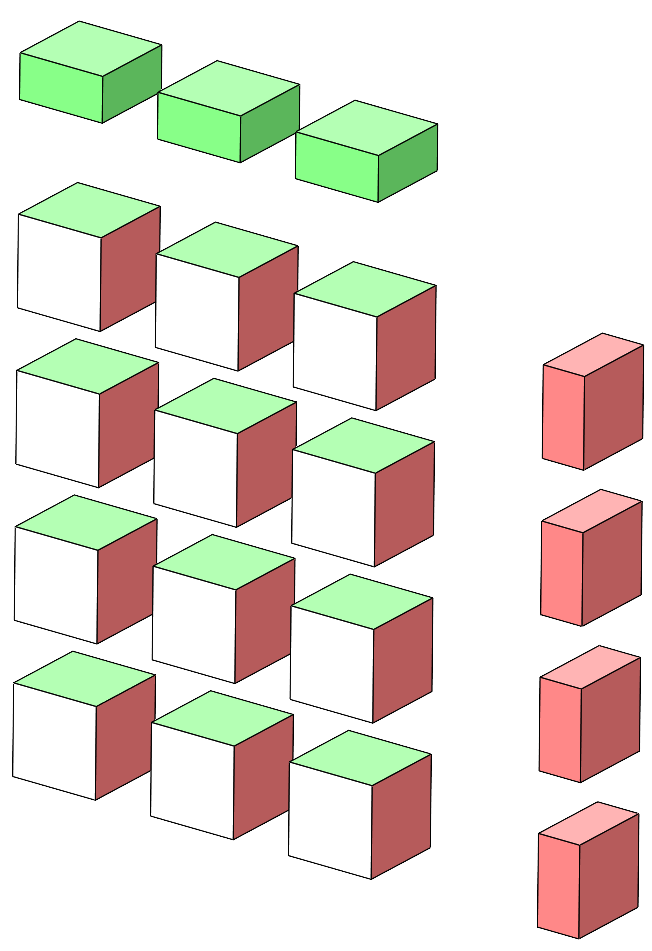
The previous page dealt with the One way anova. Two-way anova, independent samplesA general representation of a two-way anova is shown in Figure 1. This general representation is for three levels of Factor A and four levels of Factor B.
Figure 1. Representation of the two-way factorial anova.
A group of 18 subjects each drink a preparation containing amino acids, proteins, and peptides. The drink tastes (and smells) medicinal. Of this group, 9 subjects are told that the drink is expected to improve their general cognitive abilities, and 9 subjects are told that the drink is expected to specifically improve their short term memory. A second group of 18 subjects drink a preparation that tastes medicinal but contains no active ingredients. Similarly, 9 of the group are told to expect improved general cognitive ability, and 9 to expect improved short term memory. A third group of 18 subjects drink tea. Nine of the group are told to expect improved general cognitive ability, and 9 to expect improved short term memory. All 54 subjects undertake a memory test a short interval after their drink. The design of this two-way factorial anova is illustrated in Figure 2. The test scores are shown in Table 1, and the means in Table 2. Notice that these six samples are independent – they consist of different subjects. Table 1. Memory test scores for 54 subjects, 3 drink types, and 2 guidance types.
Table 2. Mean memory test scores.
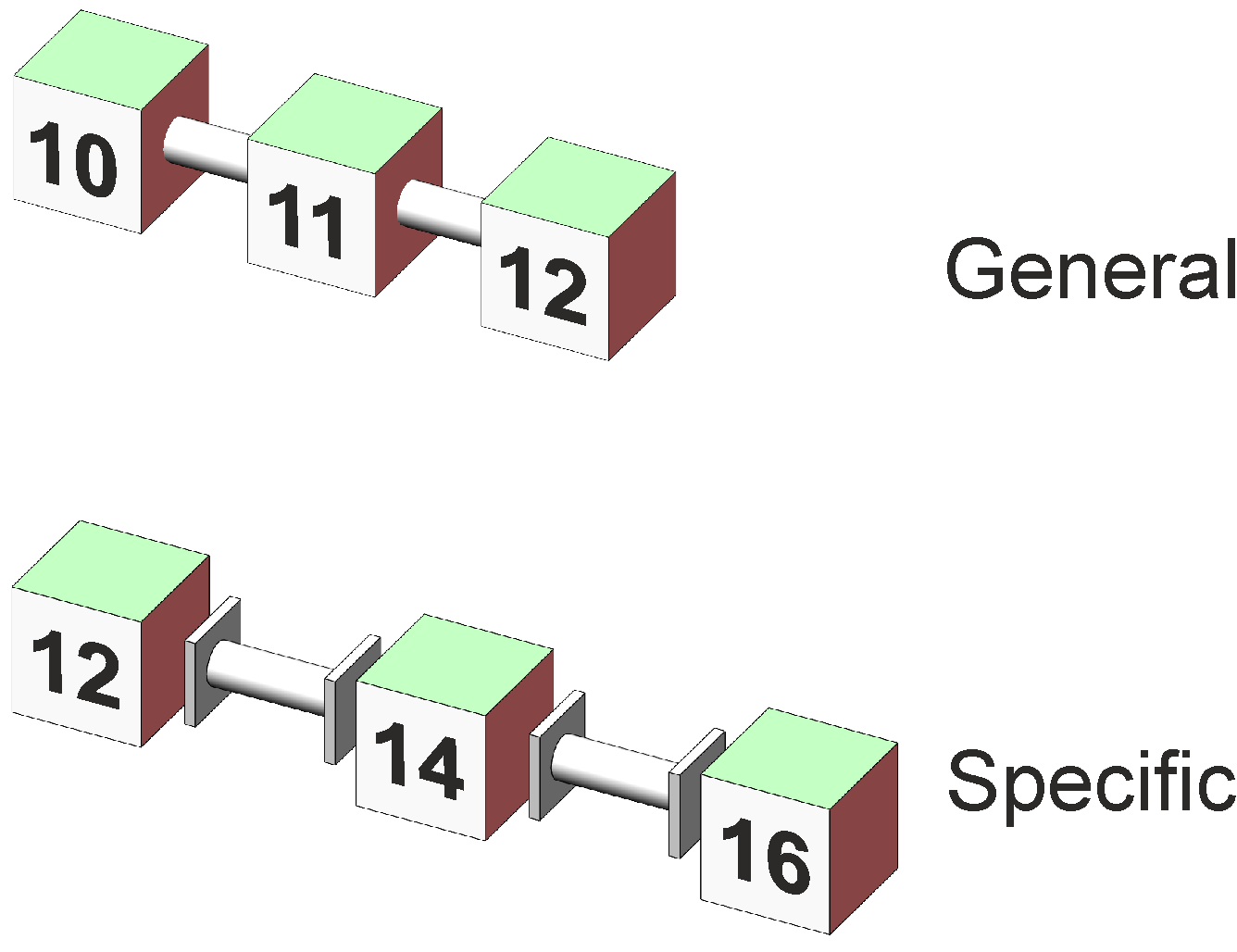
The question here is whether the protein drink improves the memory of our subjects compared to an inactive drink or to tea, and whether giving a general or specific guidance to the subjects affects improvement. The experiment is often called "two-way", but is better termed "two factor". We develop the terminology for a two-way anova. Because there are different kinds of groups we cannot easily refer to "groups" in the way we did for t-tests and the one-way anova. Instead we note that the groups in the two-way anova are made up by subjects given a type of drink and a type of guidance, and these two aspects of the design are called factors. One factor is labelled "Drink", the other factor is labelled "Guidance". A particular factor is said to have "levels", and here the Drinks factor has three levels which are labelled "Tea", "Protein" and "Inactive". The Guidance factor has two levels, "General" and "Specific". Where it is useful to refer to the six groups of subjects without specifying the factors or factor levels, reference is made to the 6 "Cells" of the design. The representation of the data continues to use cubes as the building blocks, where a cube is the mean of a set of data (or a group of subjects) which receive a particular combination of treatments, such as a protein drink with general guidance. A half-cube represents the mean of a particular level of a treatment, such as the mean of all those who received general guidance. To make the factors visually distinctive, the levels of one factor are shaded red and the other factor green. Figure 2 illustrates this representation.
Figure 2. Representation of the means of the two-way factorial design with 3 levels of Factor A and 2 levels of Factor B. An apparently trivial matter, but it is worth giving early and careful attention to the descriptions and labels for the factors, their levels, and the label for the measurement. They will appear in subsequent results tables, graphs, file names, and reports, and back-tracking to improve an earlier poor choice of label inevitably leads to inconsistencies if not errors. For example we could instead have a factor "Treatment" with levels "Control", "Medicinal", and "Placebo", and a factor "Instruction" with levels "Cognition" and "Memory". The measurement could be "Score" or "Test" or "Memory". It is usually better to provide specific rather than general or generic labels.
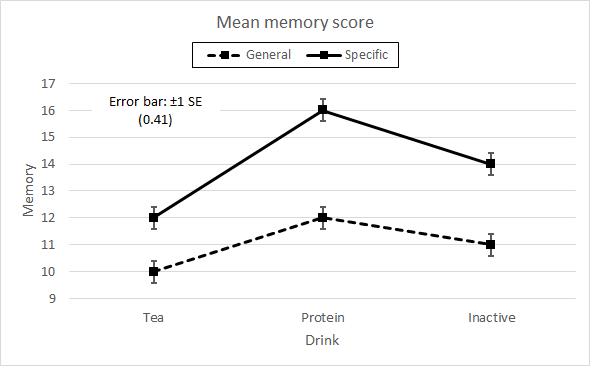
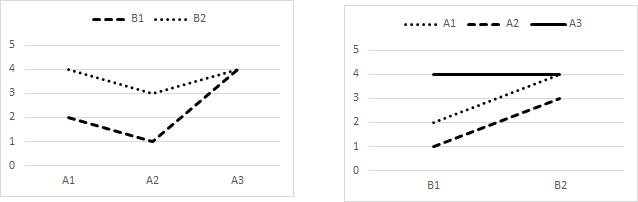
Profile plotsDraw graphs to aid interpretation. For two-factor data, there are always two profile plots and both should be drawn. One plot places the first factor on the X axis and provides plot lines for each level of the second, where the purpose of the plot is to show the trends of the second factor. The visual impact of this plot is given by the plot lines for the levels of the second factor. The other plot places the second factor on the X axis and plot lines for each level of the first, and visual impact is given by the plot line trends of the levels of the first factor. Figure 3 illustrates these two profile plots for our data. Again it is worth giving careful attention to the preparation of the graphs. Apart from using the correct labels for axes and plot lines, there are design choices of font, text size, legend placement, and in particular the styling of the plot lines. Although modern computer displays render colour very well, this is uncertain for prints. Journals and photocopiers typically simply print the grey-scale equivalent of your art work, rendering meaningless graphs and indecipherable figures. At the least, construct plot lines in a variety of dots and dashes to make sure they will come through no matter how they are reproduced.
Figure 3. Profile plots of mean memory scores for Drink × Guidance and for Guidance × Drink. These profile plots are also called interaction plots. The Guidance × Drink profile plot (right hand Figure 3) well illustrates the greater effect of specific guidance (solid plot line) for the three drinks (on the X axis). If that is the only profile plot drawn, you may easily miss the small but possibly significant difference between the drinks (three plot lines) under specific guidance (on the X axis) as shown by the other interaction plot of Drink × Guidance (left hand Figure 3). Always initially draw both plots for two factor data (§1). Note the error bars are given at ±0.41, which is the SE calculated as the square root of the average cell variance divided by n, √(1.5 / 9). It may be that the cells in your data have quite different variances and/or quite different n (§2). In this case, use the individual cell information to calculate an individual SE for each cell mean to place on the graph. §1 It is awkward to refer to "the first profile plot" and then to "the second profile plot". The first plot may be called the Drink × Guidance plot, and the second the Guidance × Drink, where the first factor mentioned is the one whose levels are represented on a plot line and the second factor mentioned is the one plotted on the X axis. It is then more natural to use the Drink × Guidance plot to visualise the differences due to Guidance, and the Guidance × Drink plot to visualise the differences due to Drink. Having drawn the interaction plots, note that they will only be needed and reported if the interaction effect is significant. Some investigators postpone drawing the two-factor profile plots until the interaction effect is known. If it is not significant, then only profile plots of main effects are required and, in general, the two-factor plots should not be interpreted or even shown in the final report of the results. §2 What might be meant by "quite different"? We can suggest that, for small n, that is, n<30, one sample size is "quite different" from another if it has fewer than half the number of subjects; one variance is "quite different" from another if it is more than 20 times larger, and one standard deviation is "quite different" from another if it is more than 4 or 5 times larger
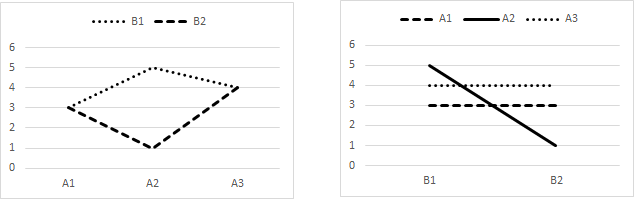
Initial interpretation — any interaction?From the profile plots, it seems that specific guidance enhances memory, compared with general guidance, in a similar way for each drink. It seems that the drinks enhance memory, or not, in a similar way for each type of guidance. The key issue to look for in each A×B and B×A interaction profile plot is whether the plot lines show the same trend or have different trends. Plot lines have the same trend if they run more or less in parallel, and have different trends if they diverge (§3). Divergence in trend is called "interaction", and is the primary reason for conducting two- or higher-factor experiments. Technically, interaction is shown when the effects of one factor are different at the various levels of the other factor. It seems there is no interaction, since the effect of Guidance looks to be similar for each drink, and the effect of Drink looks to be similar for each type of guidance. Given insignificant interaction, we carry on to determine the difference between specific and general guidance, knowing that this applies similarly to all drinks, and to determine the differences between the drinks knowing they applies similarly to both types of guidance. These overall effects of guidance and of drink are known as "main" effects. If there is interaction, the effect of Guidance, whether general or specific, depends upon which drink. If there is interaction, the effect of Drink, whether tea, protein, or inactive, depends on which guidance. Given significant interaction, we do not carry on to determine the difference between specific and general guidance overall because this does not apply similarly to the drinks. We do not carry on to determine the differences between the drinks overall because these do not apply similarly to both types of guidance. Instead, we determine the difference between specific and general guidance separately for tea, protein, and inactive drinks, and determine the differences between tea, protein, and inactive drinks separately for general and specific guidance. The effects of Guidance at each level of the Drink factor are known as the "simple" effects of Guidance, while there are the simple effects of Drink at each level of the Guidance factor. §3 These are some profile plots which show interaction effects, Figure 4. We can see that the plot lines are not all generally parallel or generally have similar trends.
Figure 4. Variety of profile plots illustrating interaction. It may be worth noting the very different visual picture given by an A×B plot compared with a B×A plot for the same data. Always plot both!
Computing the significance of any interactionInteraction is when the effects of one factor are different at the various levels of the other factor, and is conveniently labelled the "Guidance × Drink" or, equivalently, the "Drink × Guidance" interaction. Finding the interaction effect involves the removal of the main effects of the two factors to see what is left (§4). The size of an effect is measured by its variance, known as its MS in the analysis of variance. Its significance is tested against the error variance seen in the data cells, called MS(Error) or MS(Within subjects). We compute the F ratio of MS(effect) divided by MS(Error), and refer to the F distribution for its p value using the df for the effect and df(Error). The MS for the Guidance effect is based on the variance shown by the mean memory score for subjects given general guidance and for subjects given specific guidance. Similarly the MS for the Drink effect is based on the variance shown by the mean memory scores for subjects taking the protein drink, inactive drink, and tea. It is convenient to lay these mean scores out in a table of means which are arranged by Guidance and Drink, as shown in Table 2. The 6 groups in this table are called "cells". Table 2. Mean memory test scores.
From the explanations given in the One way anova page we understand that the MS of an effect is given by multiplying the variance of its means by the number of data items which make up each. There are 9 data items — 9 subjects — per cell, hence there are 18 data items which make up each drinks mean, and 27 which make up each guidance mean. The variance of the drinks means of 11,14, and 12.5 is 2.25, hence MS(Drinks) is 2.25 · 18 = 40.5 with df = 3–1 = 2. The variance of the guidance means of 11 and 14 is 4.5, hence MS(Guidance) is = 4.5 · 27 = 121.5 with df = 2–1 = 1. We remember that when we calculate the standard deviation of some numbers which are means we are effectively calculating their standard error, SE. Knowing the sample standard deviation "s", the standard error of a sample mean is usually calculated by dividing s by the square root of the number of items making up the mean, n, SE = s / √n. If we do not know the sample standard deviation but do know SE, then we can calculate s by multiplying the SE by the square root of the sample size. The same logic applies to the variance. When we calculate the variance of some numbers which are means we have effectively calculated SE2. The variance we are seeking, s2, is given by n · SE2. We calculate MS(Cells) from the variance of the cell means multiplied by 9, the number of data items which make up each cell mean. The variance of the cell means of 10, 12, 12, 16, 11, and 14 is 4.7, hence MS(Cells) is 9 · 4.7 = 42.3. The degrees of freedom for this variance is 5, being the number of cells – 1 = 6 – 1. To calculate MS(Interaction), also called MS(Drink × Guidance), MS(D×G), or sometimes generically MS(AB), we remove the variation due to the effect of Guidance and the variation due to the effect of Drink from the variation of the cell means. The careful use of the term "variation" alerts us to the need to conduct removal using the sums of squares as our measure of variation — partitioning the SS — and to then reconstruct the required MS using the partitioned df. We remember that MS = SS / df, so SS = df · MS. SS(Cells) is given by df(Cells) · MS(Cells) = 5 · 42.3 = 211.5, SS(Guidance) is given by 1 · 121.5 = 121.5, and SS(Drink) is given by 2 · 40.5 = 81. We remove the variation due to Drink and Guidance from the variation shown by the cell means to reveal the variation due to interaction: SS(Interaction) = SS(Cells) – SS(Guidance) – SS(Drink) = 211.5 – 121.5 – 81 = 9, and df(Interaction) = df(Cells) – df(Guidance) – df(Drinks) = 5 – 1 – 2 = 2. From the explanations given in the One way anova we understand that MS(Error) or MS(Within groups) is given by the average MS of the cells (§5), which for our data is (1.5 + 1.5 + 1.5 + 1.5 + 1.5 + 1.5) / 6 = 1.5. The df for MS(Error) is the sum of the df for each cell, which for our data is 6 · (n–1) = 4 · 8 = 48. SS(Error) is therefore 72. We can now complete the anova summary table and calculate the F ratios. Table 3. Anova summary.
We note the interaction is not significant. We now carry on to interpret the Guidance and Drink main effects. Note that the interaction profile plots should be placed in the bottom drawer, they are no longer relevant. §4 The term "effect" refers to a difference between one condition and another. The main effect of Guidance, for example, refers to the difference in the mean memory test score of subjects given general guidance compared with those given specific guidance (but read on). The main effect of Drink refers to the difference in the mean memory test scores of subjects taking Tea, the Protein drink, and the Inactive drink. The interaction effect refers to the differences in the mean memory test scores of each cell after the effects of Guidance and Drink have been removed. The specific value of the effect of a level of a factor is the difference between that level's mean and the overall mean of the data. For example, the mean of the subjects who drink protein is 14, the grand mean of the data is 12.5, and so the Protein effect is 1.5. In summary: The effect of a factor is given by the variance (MS) of the means of the various levels of that factor, so the effect of the Drink factor is given by the MS of the means for Tea, Protein, and Inactive drinks, in this case 40.5. The effect of a given level of a factor is given by the difference between the mean of that level and the grand mean, so in this case the effect of the Protein drink is 1.5. §5 Conceptually, MS(Error) is given by the average of the variances we have in each cell. Calculating the value of MS(Error) as the average of the cell variances requires the cells to have equal n. A different calculation is needed for unequal cell sizes.
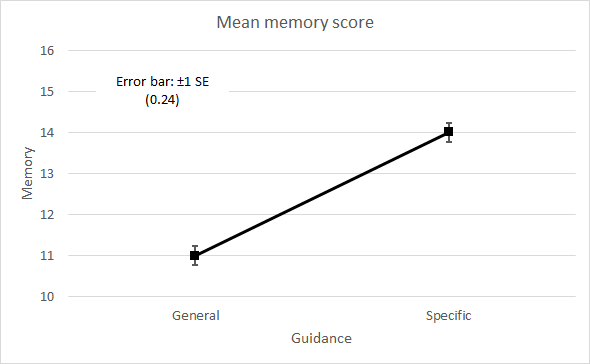
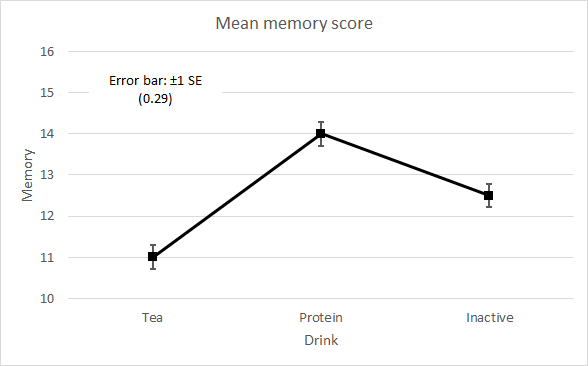
Main effects following insignificant interactionDraw the main effect profile graphs to aid interpretation. For two-factor data, there are two profile plots, one for each factor. These are shown in Figure 5. Note that SE for the guidance means is √(1.5 / 27) = 0.24, while for the drinks means it is √(1.5 / 18) = 0.29.
Figure 5. Profile plots of main effects. There is little further to do regarding the Guidance factor. The main effect of Guidance F(1,48) is 81.0 with p <.001, and its interpretation is straightforward: subjects receiving specific guidance score significantly higher on average on the memory test than subjects receiving general guidance by 3 points. Note the interpretation is in terms of the difference in mean scores between the two levels of the factor. Note also that the interpretation is entirely consistent with the picture suggested by the profile plot where the error bars show how widely the means are separated in relation to their standard error. The difference between the Guidance factor means is illustrated in Figure 6.
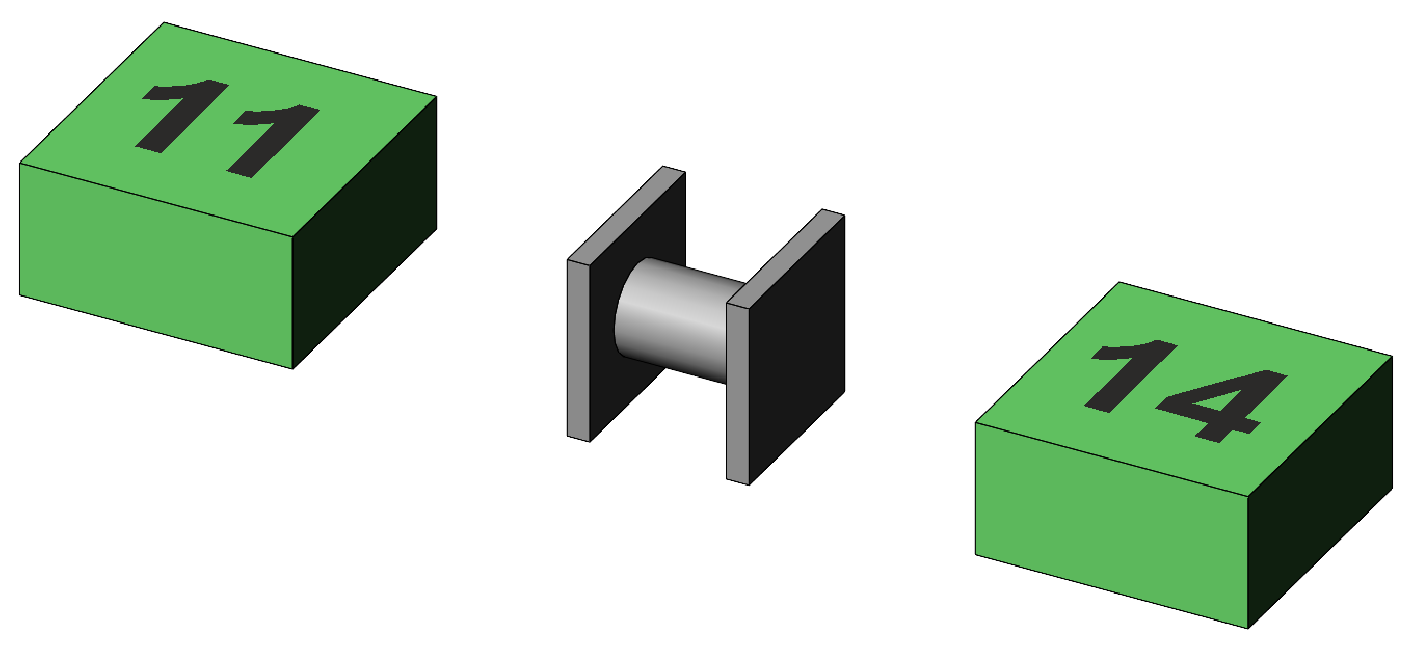
Figure 6. Representation of the main effect difference between the means for General guidance and for Specific guidance in relation to their SEdiff, 0.33. The interpretation of the Drink main effect F(2,48) of 27.0 with p <.001 is, at the least, that subjects taking the protein drink score significantly higher on average on the memory test than subjects taking tea by 3 points. But whether the protein drink mean is significantly higher than the inactive drink mean, or whether the tea mean is significantly lower than the inactive drink mean requires pairwise comparisons. Of course, the profile plot of the drinks means clearly shows wide separation between these means in relation to their standard error, but for formal reporting an F or t-test and associated p value are essential.
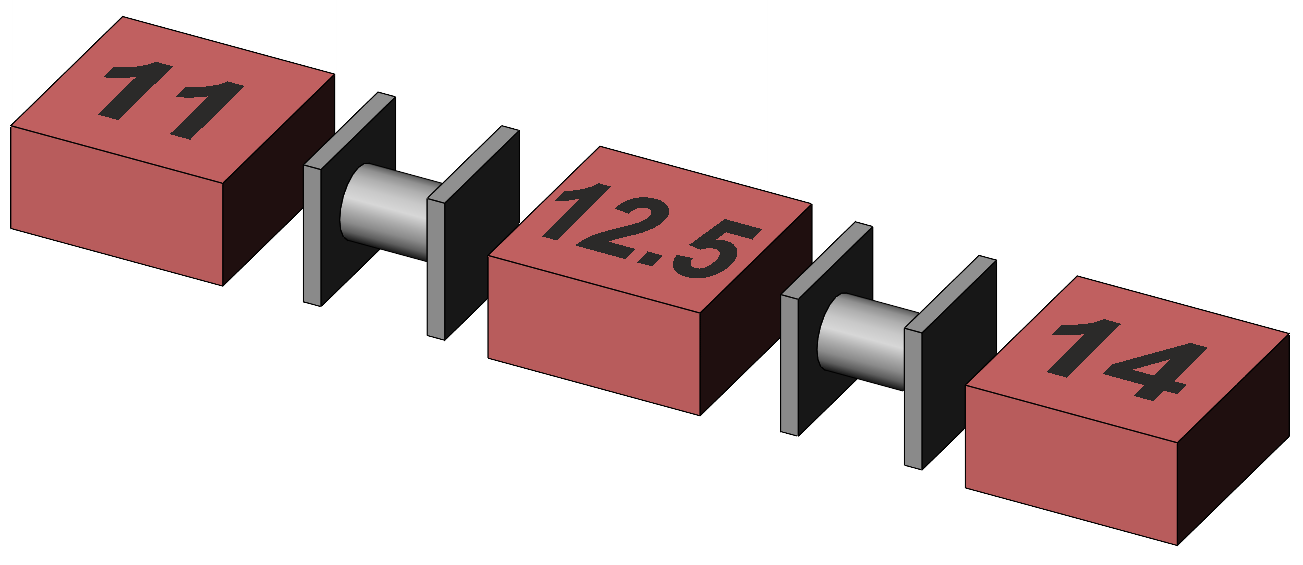
Pairwise comparisonsGiven the anova has shown a significant main effect for the Drink factor, we compare the mean Protein memory score with the mean Inactive and Tea scores, and the mean Inactive with Tea. We remember that conducting three separate significance tests inflates the family-wise Type I error rate, that simple LSD t-tests are acceptable given no more that 3 means being compared, and that Sidak or Tukey tests or corrections are otherwise indicated. A t-test for the difference between two means of the Drink factor uses a SE for the difference calculated as √ (2·MS(Error) / 18) = √ (2 · 1.5 / 18) = 0.41. We note the division by 18 because each drinks mean is based upon 18 scores. The df for the t-test are the same as those for MS(Error), 48. For the comparison between Tea and Inactive we have t = (11 – 12.5) / 0.41 = –3.67, and for the comparison between Inactive and Protein we have t = (12.5 – 14) / 0.41 = –3.67. Both have p values <.001, both are significant, and we can formally state that subjects taking the inactive drink score significantly higher on average on the memory test than subjects taking tea by 1.5 points, and that subjects taking the protein drink score significantly higher on average on the memory test than subjects taking the inactive drink by 1.5 points. These differences are illustrated in Figure 7.
Figure 7. Representation of the main effect differences between the means for Drinks in relation to their SEdiff, 0.41.
The main effect of factor A is overall the levels of factor BNote that the interpretation of the Guidance factor applies across and overall all levels of the Drink factor. The data shows there are indeed differences in Guidance effects — for example, specific guidance raises the average memory test score by 4 points for the protein drink but only by 2 points for tea — but because the interaction effect is not significant, these differences are deemed to be not significant and are ascribed to random sampling error. Notice how the plot line of the Guidance main effect profile plot is the average of the Tea, Protein, and Inactive drinks plot lines in the Guidance × Drink profile plot. Hence a main effects profile plot always consists of a single plot line. Similarly, note that the interpretation of the Drink factor applies across and overall all levels of the Guidance factor. The data shows there are differences in the Drink effect depending upon the Guidance — for example, the protein drink raises the average memory test score by 4 points under specific guidance but only by 2 points under general guidance — but because the interaction effect is not significant, these differences are deemed to be not significant and are ascribed to random sampling error. Notice how the plot line of the Drink main effect profile plot is the average of the two general and specific guidance plot lines seen in the Drink × Guidance profile plot.
Simple main effects following significant interactionFor this section, we chose to adopt a different level of significance of α = 0.10, and so declare a significant interaction effect, F(2,48)=3, p = .06. Hence, we do not interpret the Guidance and Drink F ratios, significant though they are. We retrieve the interaction profile plots from the bottom drawer and in their place stow away the main effect profile plots. We proceed with the analysis of simple main effects. For two factors there are two sets of simple main effects, a set for each factor. One set of simple main effects examines the difference between the means of General and Specific Guidance for each of the three drinks separately, hence three tests of significance, and the second set of simple main effects examines the differences between the Drink means for each of the two guidance levels separately, hence two tests of significance. Figure 8 illustrates the simple main effects of Guidance at each level of Drink: Tea, Protein, and Inactive.
Figure 8. Simple main effects of Guidance at each level
of Drink: Tea, Protein, and Inactive. The simple main effects of Guidance for Tea are given by a one-way anova of the means of general and specific guidance for Tea, being 10 and 12. There is a similar one-way anova for the Protein means, 12 and 16, and for the Inactive means of 11 and 14. Each anova tests the simple main effect MS(Guidance at Drink=Tea), MS(Guidance at Drink=Protein), and MS(Guidance at Drink=Inactive) against the error term from the two-way anova, MS(Error). The F ratio degrees of freedom are 1 and 48, being the df for the simple main effect (two means, df = 2 – 1 = 1) and the df for MS(Error) (48). (§6) We remember that the MS of an effect is given by multiplying the variance of its means by the number of data items which make up each mean, here 9. The summary table of the simple main effects for guidance is shown in Table 4. Table 4. Simple main effects for guidance.
Adding up the variation, that is the SS, for these simple main effects gives 18 + 72 + 40.5 = 130.5, and similarly the total df is 1 + 1 + 1 = 3. We can see that these are the values given by adding up SS(Guidance) and SS(Interaction) = 121.5 + 9 = 130.5 and df(Guidance) and df(Interaction) = 1 + 2 = 3. This provides us with another way of understanding the simple main effects of the Guidance factor — they are a re-partitioning of "the variation of Guidance plus the variation due to the interaction of Guidance with Drink" into "the variation of Guidance at each level of the Drink factor". We note that all three simple main effects of Guidance are significant, and we check this for consistency with the Guidance × Drink profile plot (following the initial comment provided in note §1 that the Guidance × Drink plot is the one which better shows differences between guidance). We see large gaps between the guidance means at each drinks type with no overlap of their error bars, consistent with the large F ratios reported in Table 4. Figure 9 illustrates the simple main effects of Drink at each level of Guidance: General and Specific.
Figure 9. Simple main effects of Drink at each level of Guidance: General and Specific. Two one-way anovas using MS(Error) from the two-way analysis. The simple main effects of Drink for general guidance are given by a one-way anova of the means of Tea, Protein, and Inactive for general guidance, being 10, 12, and 11. There is a similar one-way anova for the simple effects of Drink for specific guidance with means, 12, 16, and 14. Each one-way anova tests the simple main effect MS(Drink at Guidance=General) and MS(Drink at Guidance=Specific) against the error term from the two-way anova, MS(Error). The F ratio degrees of freedom are 2 and 48, being the df for the simple main effect (three means, df = 3 – 1 = 2) and the df for MS(Error) (48). We remember that the MS of an effect is given by multiplying the variance of its means by the number of data items which make up each mean, here 9. The summary table of the simple main effects for Drink is shown in Table 5. Table 5. Simple main effects for Drink.
Adding up the variation, that is the SS, for these simple main effects gives 18 + 72 = 90, and similarly the total df is 2 + 2 = 4. We can see that these are the values given by adding up SS(Drink) and SS(Interaction) = 81 + 9 = 90 and df(Drink) and df(Interaction) = 2 + 2 = 4. As before, this provides us with another way of understanding the simple main effects of the Drink factor as a re-partitioning of "the variation of Drink plus the variation due to the interaction of Guidance with Drink" into "the variation of Drink at each level of the Guidance factor". §6 We may notice that there are two means being compared here, and so we could instead conduct an equivalent analysis by using a t-test for the difference between general and specific guidance for Tea, for Protein, and for Inactive. We would use SE calculated as √ (2·MS Error / 9), each mean being compared is based upon n=9 data items, with df = 48, that is, df for MS(Error).
"Simple" pairwise comparisons following significant simple main effectsThe simple main effects of Guidance at each drink are significant. Usually there would be no need for pairwise comparisons because there are only two levels of guidance. There are nevertheless illustrated in Figure 10.
Figure 10. Illustration of pairwise comparisons
following significant simple main effects of Guidance at each level of Drink.
We note that both simple main effects of Drink are significant. As before with the analysis of three or more means, a significant omnibus test allow us to conclude that, at the least, the largest mean is significantly larger than the smallest, but whether the other means are significantly different must be shown by a formal examination of pairwise comparisons. It could be useful to call these pairwise comparisons "simple", but this terminology is not one generally adopted in the literature. Such comparisons are assumed "simple" by their context, which is that they follow significant simple main effects. The simple main effects anova has shown a significant simple main effect for the Drink factor at Guidance = General. We compare the mean Protein memory score with the mean Inactive and Tea scores, and the mean Inactive with Tea, for the general guidance cells. We remember that conducting separate significance tests, 3 for each family in this case, inflates the family-wise Type I error rate; that simple LSD t-tests are acceptable given no more that 3 means being compared; and that Sidak or Tukey tests or corrections are otherwise indicated. A t-test for the difference between two cell means uses SE calculated as √(2·MS error / 9) = √(2 · 1.5 / 9) = 0.58. We note the division by 9 because each cell mean is based upon 9 scores. The df for the t-test are as for MS(Error), 48. For the comparison between Tea and Inactive when guidance is general we have t = (10 – 11) / 0.58 = –1.73, p = .09; between Inactive and Protein we have t = (11 – 12) / 0.58 = –1.73, p = .09; and between Tea and Protein we have t = (10 – 12) / 0.58 = –3.46, p < .001. We see that, when guidance is general, only the difference between Tea and Protein is significant. The differences between Tea and Inactive, and Inactive and Protein, are not significant. A check with the Drink × Guidance profile plot shows the relatively small gaps between the Drink means for general guidance, consistent with the pairwise comparisons. Following the significant simple main effect for the Drink factor at Guidance = Specific, we compare the mean Protein memory score with the mean Inactive and Tea scores, and the mean Inactive with Tea, for the specific guidance cells. For the comparison between Tea and Inactive when guidance is specific we have t = (12 – 14) / 0.58 = –3.46, p < .001; between Inactive and Protein we have t = (14 – 16) / 0.58 = –3.46, p < .001; and between Tea and Protein we have t = (12 – 16) / 0.58 = –6.92, p < .001. We see that, when guidance is specific, all the differences between Drink are significant. A check with the Drink × Guidance profile plot shows the relatively large gaps between the Drink means for specific guidance, consistent with the pairwise comparisons.
Figure 11. Illustration of pairwise comparisons
following significant simple main effects of Drink at each level of Guidance.
SummaryInteraction in the analysis of variance is when the effects of one factor are different at the various levels of the other factor. It is seen in an interaction profile graph which plots one factor on the X axis and the levels of the second factor as plot lines. Plot lines which are more or less parallel show little interaction; plot lines which diverge are indicative of interaction. Testing for interaction is the primary purpose of constructing an investigation involving two factors whose data is analysed by a two-way or two-factor anova. An interaction effect is what is left after the removal of the main effects of the two factors. The size of an effect is measured by its variance, its MS in the analysis of variance. Its significance is tested against the error variance seen in the data cells, usually called MS(Error). We compute the F ratio of MS(effect) divided by MS(Error), and refer to the F distribution for its p value using the df for the effect and df(Error). A significant interaction requires a follow-on analysis of simple main effects, where the effects of one factor are analysed and interpreted separately at each level of the other factor. Analysing the simple effects of a single factor at a given level of another is, in essence, conducting a one-way anova, the key difference being that MS(Error) for the one-way is taken from and equal to MS(Error) in the parent two-way analysis. An insignificant interaction allows the analysis and interpretation of each factor main effect, being an effect which applies similarly to all levels of the other factor. Main effect profile plots comprise a single plot line, being the average over the levels of the other factor. Where a main effect or simple main effect is significant, it is further analysed using pairwise comparisons. Again, pairwise comparisons are, in essence, LSD t-tests where SE is based upon MS(Error) from the parent two-way analysis.
Using ExcelThe workflow for the general two-way anova for p levels of Factor A and q levels of Factor B with cells of n subjects is (1) lay out a table of A×B cell means (§7), the row and column factor A and B means, and the grand mean; (2) calculate the variance of the cell means; (3) multiply this variance by n and then by pq–1 to give the SS(Cells); (4) calculate the variance of the Factor A means and the variance of the Factor B means; (5) multiply the Factor A variance by qn and then by p–1 to give SS(Factor A), also called SS(A), and the Factor B variance by pn and then q–1 to give SS(Factor B), also called SS(B); (6) subtract SS(A) and SS(B) from SS(Cells) to give SS(Interaction), also called SS(A×B); (7) calculate MS(Interaction), also called MS(A×B), as SS(A×B) / (p–1)(q–1); MS(A) as SS(A) / (p–1); and MS(B) as SS(B) / (q–1); (8) calculate MS(Error) as the average of the cell variances; (9) calculate the F ratios MS(A) / MS(Error); MS(B) / MS(Error); and MS(A×B) / MS(Error); (10) using df(A) = p–1, df(B) = q–1, df(A×B) = (p–1)(q–1), and df(Error) = pq(n–1), calculate the probability of the F values using the function F.DIST.RT(F value, df(effect), df(Error)). §7 By convention, an A×B table of cell means is laid out with the Factor B levels in columns and the Factor A levels in rows. This is of little relevance when the two factors represent independent groups of subjects, but becomes relevant if multiple (repeated) measures are taken from groups of subjects. The multiple measures are usually distributed as Factor B in columns, and the subjects are listed row by row, grouped into their various levels of Factor A. This arrangement is the usual form of the data table in Excel where each subject has a row of data, and is the usual form as might be submitted to a statistical package such as SPSS for analysis.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
©2025 Lester Gilbert |