![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
There are a number of pages related to the simulator:
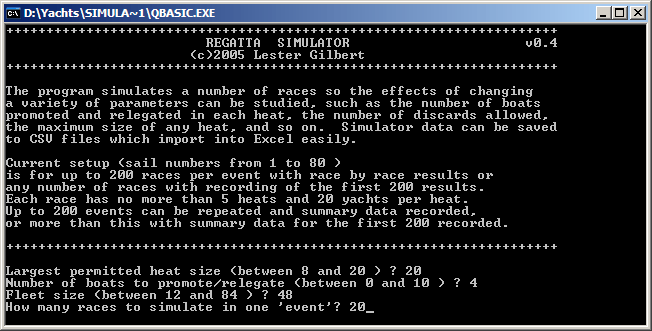
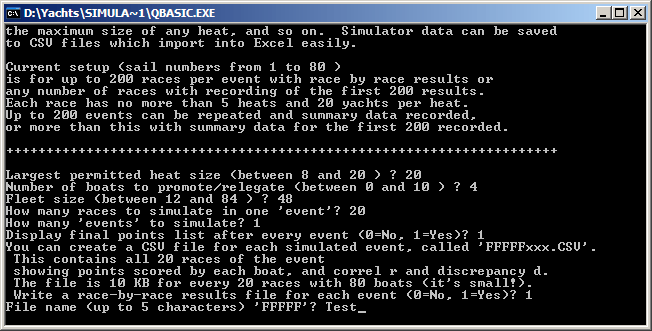
The simulator calculates the heat sizes for Race 1, Race 2, and following, depending upon your preferences for limiting heats, promoting boats, and the size of the regatta you want to simulate.
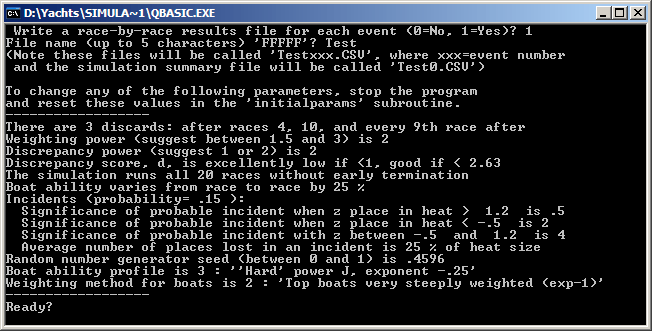
While there are standard discards after 4, 10, and every 9th race thereafter, you can change this pattern to no discards at all, or some other rate of discards after every Nth race. The heart of the simulator is to take a heat of boats of varying ability and 'run' the heat with two random components. One component is an estimate of the finishing places, given by ABILITY + VARIANCE * (quasi-Gaussian random number - 0.5). The simulator uses a crude method of converting uniformly distributed random numbers into a Gaussian distribution -- it takes 6 of them and uses their average. By the central tendency theorem, the resulting number is pretty close to being normally distributed. The quasi-Gaussian random numbers range between 0 and 1, so subtracting 0.5 means sometimes the ability will be reduced, and sometimes increased, by an amount of variability. The "better" boats have higher ability values, so tend to have higher estimated finishing places. The simulator provides five ability profiles for the fleet. There are two simple linear distributions, a cosine-based "S" distribution, and two "J" distributions which give high ability to the first few boats. These ability profiles are discussed in detail on the parameters page. The second component of the simulator heart is to see if a boat has an "incident" in its heat. The probability of an incident is a simulator parameter. Set it to 0, and there are no incidents. Set it to 1, and every boat has one. The simulator suggests a value of 0.15 or 15%. If the boat has an incident, there is then a chance that it will lose a random number of places, depending upon where in the heat it is at the time of the incident. Boats at the front of the heat tend to have very few incidents which lose them places, boats at the back of the heat tend to have some, but it is boats in the middle which are most likely to suffer. These details can be changed. The simulator provides a measure of how well the race outcomes match the boat abilities, called "discrepancy". It also calculates a standard measure of correlation, r. The discrepancy measures how far away a boat is from its expected position. The simulator provides five methods of weighting the event outcomes, discussed in detail on the parameters page. Given the weights, the simulator also allows you to decide how significant it is if a boat is "out of expected position". You can raise this difference to a power to make bigger gaps more significant.
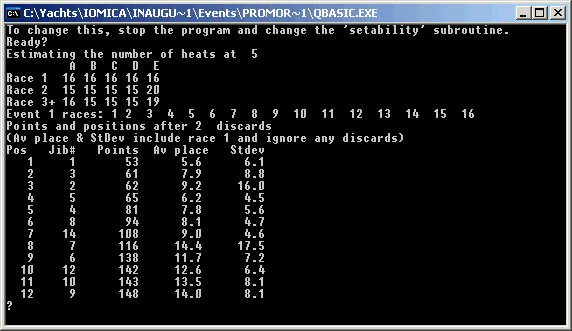
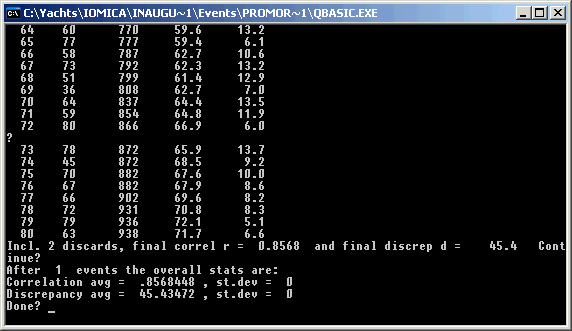
These are two example screens of the simulator output. The first shows the results for 80 boats after 16 races and 2 discards, and as expected jib no 1 is in first place. However, boats 2 and 3 have exchanged places, and so on. It is pretty close, with boat 2 on 61 points, and boat 3 on 62.
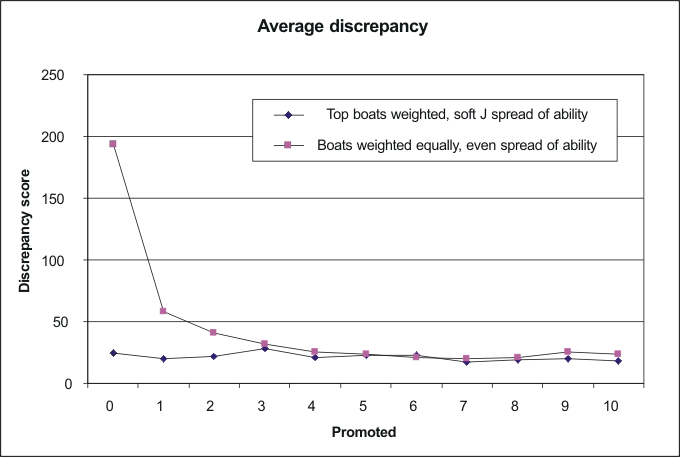
Here are some sample runs, where the simulator CSV output files were imported into Excel to make the graphs. The 'discrepancy' is the measure of how 'out of position' a boat is, weighted according to one or other of the weighting methods. We imagine that lower, smaller discrepancy scores are better. In the first graph, a fleet of 48 boats was set off on marathons of 50 events at a time. Each event involved 20 races and 3 discards. For one set of 50 events, boats were not promoted at all (they remained in the heat they achieved in Race 1, the seeding race). In a second set of 50 events, one boat was promoted per heat, and so on for 2, 3, ..., up to 10 promotions per heat. The graph shows how the 'discrepancy' fell as the number of boats promoted per heat increased, but it also shows how this effect levelled out at around 4 boats promoted per heat, when the boats were weighted equally. Notice that, if only the top boats were weighted, there was much less evidence of a 'promotions' effect.
As an overall summary of conclusions, the above graph shows that more promotions per heat give 'better' results when an egalitarian weighting method is used, while this is less significant if only the results from the top boats are weighted. Here are some sample graphs of what kinds of 'discrepancy' values result from what kinds of simulator outputs, when the discrepancy scores weight the top boats heavily and more or less ignore the lower-placed boats. The discrepancy scores from the seeding races are ignored here. Linear, evenly-spaced abilities:
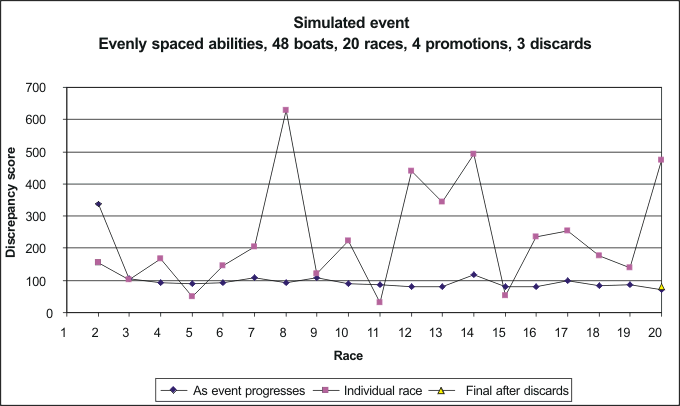
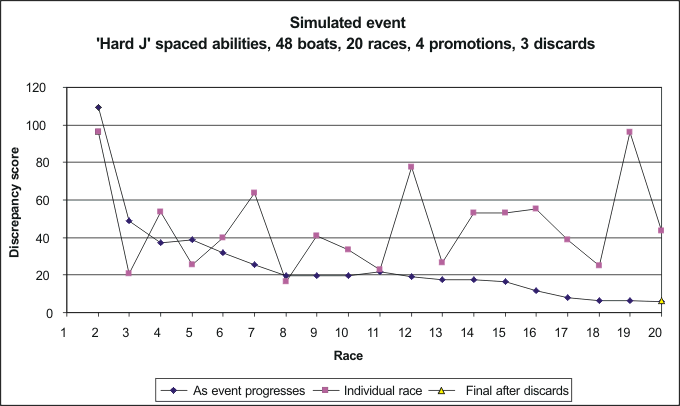
Position Jib Points 1 2 48 2 3 64 3 1 67 4 5 82 5 4 87 6 9 95 7 7 104 8 8 110 9 10 131 10 6 154Discrep = 80.3 The event has quite large fluctuations in the results of individual races, discrepancies up to around 600, but overall the placings settle down quickly to an on-going discrepancy level of around 100. The final discrepancy is 80, and the final top-10 places are shown. We see that most of the top boats are 'out of position' to some degree, and this amount of discrepancy between simulated result and theoretical ability yields a 'discrepancy score of 80'. 'Hard' J-spaced abilities Position Jib Points 1 1 17 2 2 41 3 3 44 4 4 69 5 5 81 6 6 120 7 7 138 8 9 150 9 11 154 10 8 165Discrep = 6.2 The 'steep, hard' J ability spread in the fleet means that the jib numbers are in pretty much in their expected positions at the end of the event, and this is shown by the very low final discrepancy score. Most of the boats are in the positions that match their abilities, and this pattern yields a very low discrepancy score of '6'. The graph shows the systematic decrease in discrepancy as the event progresses. You can see that jib no 1 won every race, for example. Cosine-S-spaced abilities
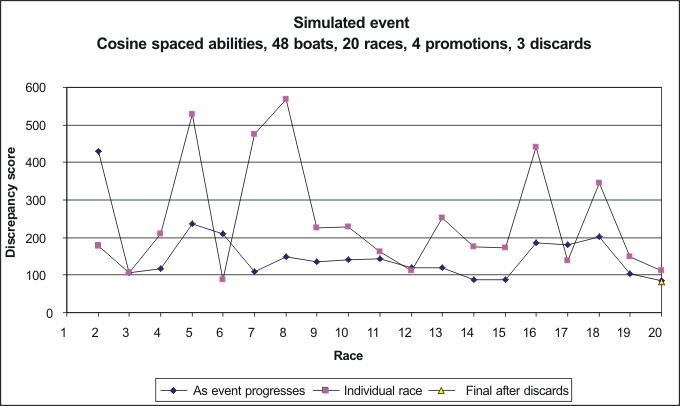
Position Jib Points 1 2 56 2 3 59 3 5 73 4 4 85 5 1 88 6 9 93 7 7 127 8 8 128 9 11 138 10 6 142Discrep = 82.4 Where boat abilities were bunched in an "S" curve, some at the top and some at the bottom, the simulation shows high discrepancy scores race by race, and considerable variation in discrepancy. Like the earlier "evenly-spread" simulation, the event settles down with a high discrepancy somewhere between 100 and 200, and only gets to a final discrepancy of 82 in the last race. Again, the top boats are mostly out of position somewhat, and the discrepancy score of 82 indicates they are about as out of position as was found with the earlier 'evenly-spread' simulation. 'Soft' J-spaced abilities
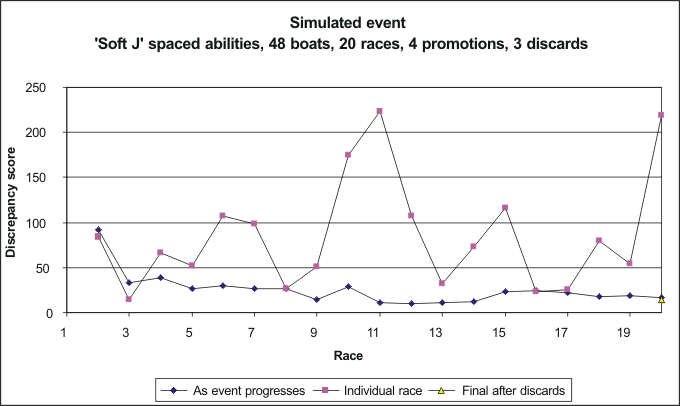
Position Jib Points 1 1 25 2 2 38 3 4 61 4 5 65 5 3 80 6 6 90 7 7 105 8 10 142 9 8 144 10 11 155Discrep = 14.9 The results from a simulation with a 'soft' J spread of abilities is somewhere between the earlier simulations. The discrepancy score of 15 indicates the boat positions are better aligned with their abilities that from the cosine 'S' or 'evenly-spaced' simulations, but not as well as the 'hard' J simulation. There are, of course, a number of issues to consider before these results can be taken as reasonable. The most important is the quality of the QBASIC random number generator, and it must be said that this generator is known to be a little dodgy. UPDATE: Not as dodgy as I thought. Some quality investigations are reported here. |
|
©2025 Lester Gilbert |